


Do Vision Models Suffer From Myopia?

Here’s what you need to know:
A recent study suggests that vision models like GPT-4o may suffer from blurry vision or ‘myopia’.
Researchers tested several models on a series of tasks designed to evaluate what vision models see when looking at colored lines and shapes.
This type of research is crucial in helping us understand what these models are good at and where they break down.
↓ Go deeper (12 min)

In humans, nearsightedness is a common condition in which close objects look clear but far objects look blurry. The medical term for nearsightedness is myopia.
A recent preprint paper claims that the state-of-the-art vision models (VLMs), like GPT-4o and Gemini-1.5 Pro, may suffer from something that resembles myopia, when tested on visual tasks similar to the ones given to humans by optometrists. These are extremely simple visual tasks that involve lines, circles, and squares.
The experiments suggest these models perceive fine details as blurry, hence the analogy with myopia. Because the paper is so interesting, I’ll cover it in detail. If you just want to read my closing thoughts, feel free to skip to the closing thoughts at the end.
#1: Counting line intersections
The researchers test the models on seven tasks, the first is counting intersections of lines.
“Given the impressive accuracy of VLMs on answering questions on diagrams and charts (e.g., Sonnet-3.5 scoring 94.7% on AI2D and 90.8% on ChartQA) [1], a reasonable hypothesis is that VLMs must be able to see whether two graphs intersect in a chart.”
They created 150 images of two lines, one red, one blue, drawn on a white canvas and ask the different vision models a simple question: How many times do the blue and red line plots cross each other?

Models score far from flawless on this task, despite its simplicity. Accuracy in detecting 0, 1 or 2 intersections ranges between 45% to 80%, with GPT-4o performing worst.
#2: Two circles
The second task is just as straightforward as the first one.
“In contrast to Task 1 where we tested VLMs on thin lines, here we evaluate their ability to perceive interactions between larger objects — specifically, two same-sized filled circles. This task assesses VLMs’ capability to detect (1) small gaps between circles and (2) overlapping circles.”
The researchers generated a grand total of 672 images of two circles on a white canvas, varying in size and distance.

Again, you would assume a simple test like this would be a homerun for these vision models, but with an accuracy between ∼73–93%, they are far from reliable.
#3: Encircled letters
The next task is looking at a picture of a word and seeing which letter is encircled with a big red circle.
Consistent with prior reports [2][3][4], we find that VLMs can 100% accurately identify a primitive shape (e.g., a red circle ⭕)[2] and can perfectly read an English word (e.g., Subdermatoglyphic) alone. Here, we superimposed the red circle on every letter, one at a time, in the word, and ask VLMs to identify which letter is being circled.
To adequately test this, the researchers use different line-thickness levels, font sizes and words. They tested for the words Acknowledgement, Subdermatoglyphic, and a random string of letters.

Again, the task is all but trivial. When making mistakes, the AI tends to predict letters adjacent to the circled one. Most models perform slightly better on the two English words compared to the random string, suggesting that knowing the word might helps make an educated guess.
#4 & 5: Counting overlapping or nested shapes
Next up is counting shapes that are nested or overlapping.
“Aligned with prior research [4], we also find VLMs to be able to count disjoint circles. Yet, here, we test VLMs on counting circles that are intersecting like in the Olympic logo—a common cognitive development exercise for preschoolers [5][6].
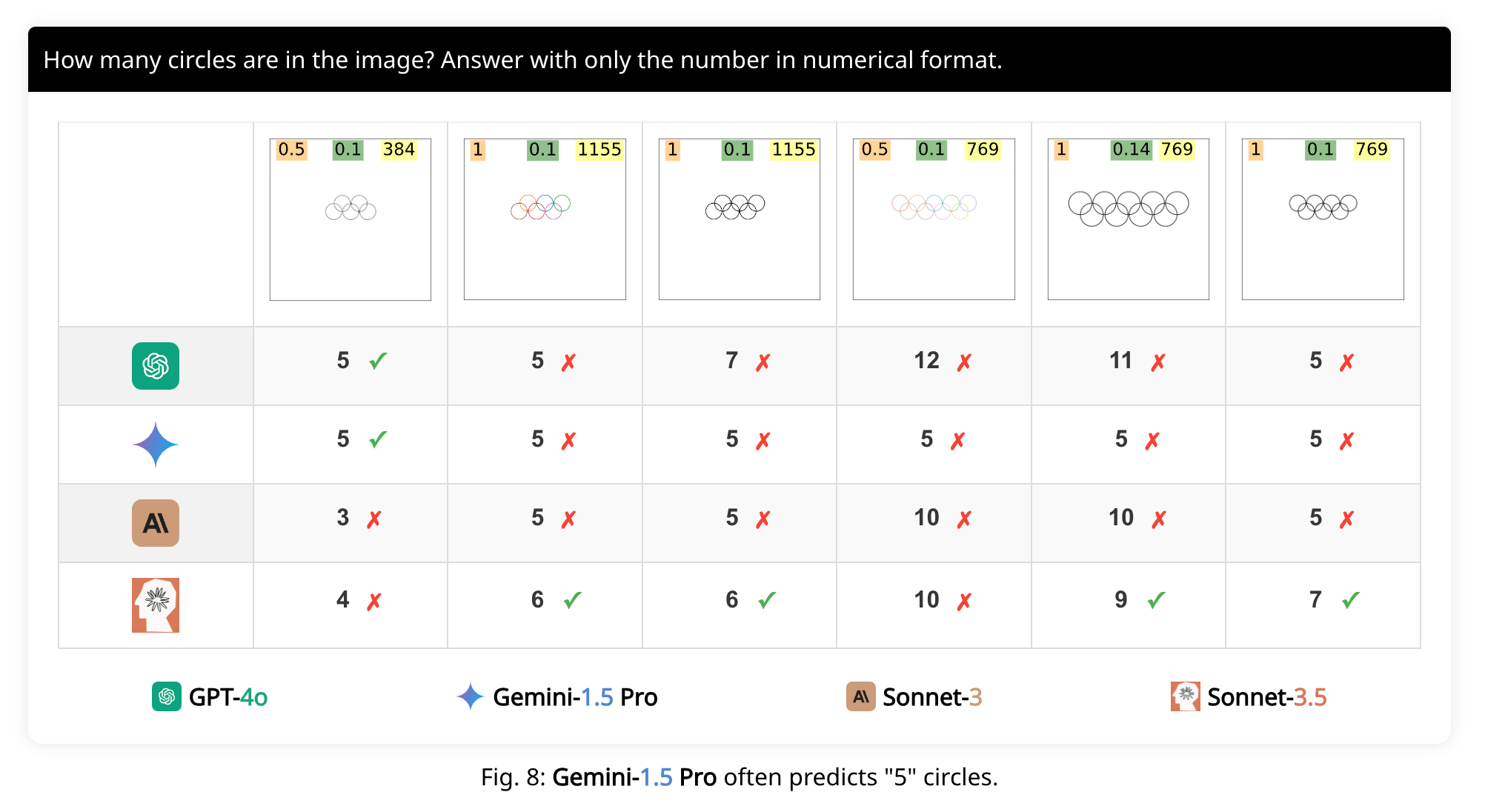
And, also:
Motivated by the findings that VLMs struggle in counting the intersected circles, here, we arrange the shapes differently so that their edges do not intersect. That is, each shape is nested entirely inside another. For completeness, we test squares in this task.

Counting overlapped circles is not easy to VLMs regardless of circle colors, line widths, and resolutions. Gemini-1.5 often predicts “5” regardless of the actual circle count, suggesting a strong bias towards the well-known Olympic logo. Only Sonnet-3.5 can count 5 overlapping pentagons.
Interestingly, GPT-4o and Sonnet-3 are unable to reliably count even two nested squares. So, again, disappointing results.
#6: Counting rows and columns
The penultimate task: counting the rows and columns in a table.
“What about adjacent shapes? Here, we tile up shapes (specifically, squares) into a grid and challenge VLMs to count—a task that is supposedly simple to VLMs given their remarkable performance (≥ 90% accuracy) on DocVQA, which includes many questions with tables.”
To simplify the task, the research simply ask the models to count the number of rows and columns in a given table. That’s all.

All models struggle, performing worse than guessing, to count the exact number of rows and columns in an empty grid. This finding suggests that while they can extract content from tables to answer table-related questions, they cannot clearly “see” a table cell-by-cell.
#7: Tracing and counting paths
Last but not least, the researchers test models’ ability to recognizing a path of a unique color and trace it from a given starting point to its destination: an important task in reading maps.
“From a subway map, we randomly pick 2 stations and prompt every model to count the single-colored paths between them. We then extract answers from the templated answers and compare them with the groundtruth.”

Shockingly, even when there is only one path between two stations, no model answers with 100% accuracy. The predictions are often wrong and most of models perform worse as the complexity of the maps increases.
Closing thoughts
A commonly heard critique is: “Oh, these tests are just designed to ‘trick’ our models”. I don’t agree. Honestly, I feel that anyone should celebrate this type of research, as it is crucial in helping us understand where these models break down.
The simple nature of these tests is telling. We’re reminded of the ARC benchmark, made up of puzzles that can be solved by a 5-year old. The big difference with ARC is that it tests for reasoning, whereas this benchmark is simply designed to evaluate what vision models “see” when looking at colored lines and shapes.
Going off more established vision benchmarks or well-marketed use cases like Be My Eyes, it’s easy to get overexcited and over-attribute qualities to AI. If anything, this paper demonstrates there are still major gaps to what AI can and cannot do, and that, as we’ve seen time and time again, problems confound models in unexpected ways.
Luckily, we can see clearer now.
Hey, if you came this far…
Did you know you can support this newsletter via donations? Any contribution, however small, helps me allocate more time to the newsletter and put out the best articles I can.
Become a donor. Cancel anytime.
Nice find, Jurgen. I wonder if the hype is so strong that many people would be surprised by the fact that visual models are blind.
I would oppose the use of human sight-related terminology like "myopic". We'll have a barrage of articles about how lenses are easy and the next breakthrough is just around the corner... My understanding is that these vision models are broadly clip-based and have very little capability for positional accuracy.
I'd say they are conceptually fuzzy rather than vision-fuzzy... The latent space (where they approximate meaning) is an abstract mess, the object recognition is fuzzy and imperfect (but is getting better through exhaustive training) and then you add the interpretative bullshit of the Language Model interfacing with the visual aspect. Due to the latter part alone the fact is we don't know what the visual model sees if we try to establish it through prompting the LLM - like me asking you to explain what your dog sees. In fact the LLM interface happens in two places: task setting and outcome interpreting, so it's like me asking you to ask your dog to perform a task and then you explain to me what it was thinking at the time - I end up knowing very little about your dog...
I all on favour of grounding research though. I'd love for it to be done on raw visual analysis APIs rather than the LLM combines, but I don't think many companies exposed the API itself for public use.
Jurgen, fascinating post. I remain intrigued by how it is both similar and unalike we humans.