
What AI Engineers Can Learn From Wittgenstein

Key insights of today’s newsletter:
Ludwig Wittgenstein, the Austrian philosopher, wrote extensively about language and its intricacies.
His ideas are especially relevant for anyone working in AI, because his views on language help us better understand the limitations of large language models.
This essay explores those ideas, what you can take away from them, and why learning the meaning of words doesn’t necessary equate to learning something about the world.
↓ Go deeper (10 min read)

This might be a bit of an odd question, but does someone who knows the meaning of all the words know anything about the world? And where do new words come from?
In the story of Genesis, God creates the Garden of Eden and brings all the animals to Adam to see what he will name them. Adam names all the cattle, the birds in the sky, and even the wild animals.
It’s a very human thing to do. We point to things and give it a name. It’s most likely how early language evolved. First came words, then sentences and then whole stories — a process that took us over 100,000 years — which ultimately allowed us to communicate increasingly complex ideas, from religion to human rights to the concept of the nation state. In a way, language is the first and most powerful tool ever created.
In Philosophical Investigations (1953), published posthumously, the philosopher Ludwig Wittgenstein investigates the relationship between words and their meaning. To grasp the meaning of a word, he writes, you have to look at its use. He argues that not only have words meaning in relation to other words, the meaning of a word changes through its use. Language games, Wittgenstein called them, or Sprachspiel in German.
Take the word: nice. It originally comes from the Latin word nescius, which meant “ignorant”. The word entered the English language through Middle French in the 14th century, and was used to describe someone stupid or foolish. By the 18th century, however, the meaning shifted to describe someone who was “agreeable, “thoughtful,” or “kind.” Pretty much the opposite of what it used to mean.
Or what about words that have no equivalent in another language? The word Tsundoku (Japanese), for example, describes the act of acquiring books and letting them pile up unread. Or Ya'aburnee (Arabic), an expression that roughly translates to “You bury me”, which is used to express profound love for someone; a love that is so all-consuming that losing this person would literally bury us.
What these examples show is that words and their meaning aren’t static. Language is alive. It’s actively being shaped by us, and surprisingly, it plays a crucial role in understanding AI.
“You shall know a word by the company it keeps”
In 2019, Melanie Mitchell published her book Artificial Intelligence: A Guide for Thinking Humans, in which she writes:
“The NLP research community has proposed several methods for encoding words in a way that would capture such semantic relationships. All of these methods are based on the same idea, which was expressed beautifully by the linguist John Firth in 1957: “You shall know a word by the company it keeps.”
That is, the meaning of a word can be defined in terms of other words it tends to occur with, and the words that tend to occur with those words, and so on. Abhorred tends to occur in the same contexts as hated. Laughed tends to occur with the same words that humor finds in its company.”
Large language models are the latest and by far the most ambitious attempt at teaching computers how to talk. As Mitchell explains it, it’s inspired by this very simple yet powerful idea: what if we could calculate all the ways in which words appear next to each other?
By ingesting massive amounts of text data, LLMs are trained to do exactly that. It works according to a relatively simple learning algorithm that predicts the next token (i.e. word or part of a word). I’ll spare you the technical details, but after training (a process which can take several months) you end up with a so-called ‘pre-trained model’ that has worked out all the combinations in which words appear next to other words, and how they relate. You can see it as a language map. A map that allows the LLM to navigate and respond to a wide range of queries or ‘prompts’, simply by predicting what’s likely to come next.
A common misconception about LLMs is that they get smarter over time. Simon Willison explained this recently on his blog:
ChatGPT and other similar tools do not directly learn from and memorize everything that you say to them. This can be quite unintuitive: these tools imitate a human conversational partner, and humans constantly update their knowledge based on what you say to to them.
(…)
In the case of a “conversation” with a chatbot such as ChatGPT or Claude or Google Gemini, that function input consists of the current conversation (everything said by both the human and the bot) up to that point, plus the user’s new prompt.
Every time you start a new chat conversation, you clear the slate. Each conversation is an entirely new sequence, carried out entirely independently of previous conversations from both yourself and other users.
Understanding this is key to working effectively with these models. Every time you hit “new chat” you are effectively wiping the short-term memory of the model, starting again from scratch.
The key takeaway here is that any knowledge these models have distilled during their training process is pretty much frozen in time.
“The map is not the territory”
From that, an interesting question arises: when a LLM creates this language map, does it also learn something about the world?
The answer is not obvious. Philosopher Alfred Korzybski famously said “the map is not the territory” and “the word is not the thing.” According to Korzybski, many people confuse maps with territories, that is, confuse conceptual models of reality with reality itself. It shares some resemblance with Wittgensteins ideas, which is not entirely surprising, given that Korzybski has not only has read Wittgenstein’s work, but even admitted he and his wife Mira loved it so much they would read from it to each other in bed.
I say this because some of the most renowned AI engineers that pioneered today’s foundation models — Karpathy, Sutskever and others — are convinced that LLMs have internalized a ‘world model’. It must have, they argue, given what they’re are capable of.
At the same time, we also know LLM-powered assistants like ChatGPT, Gemini and Grok can make very, very silly mistakes. Here’s an example shared by cognitive scientist and author Gary Marcus in a recent post:
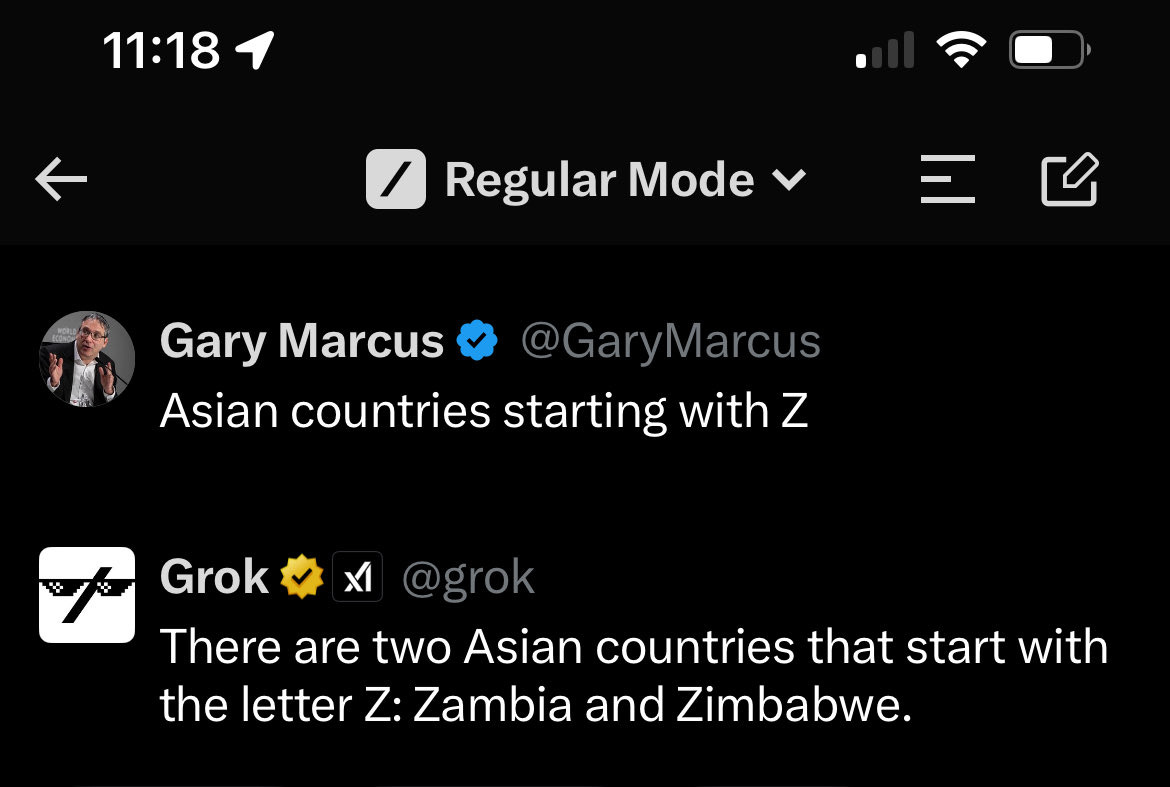
Here’s another one I was able to replicate myself:
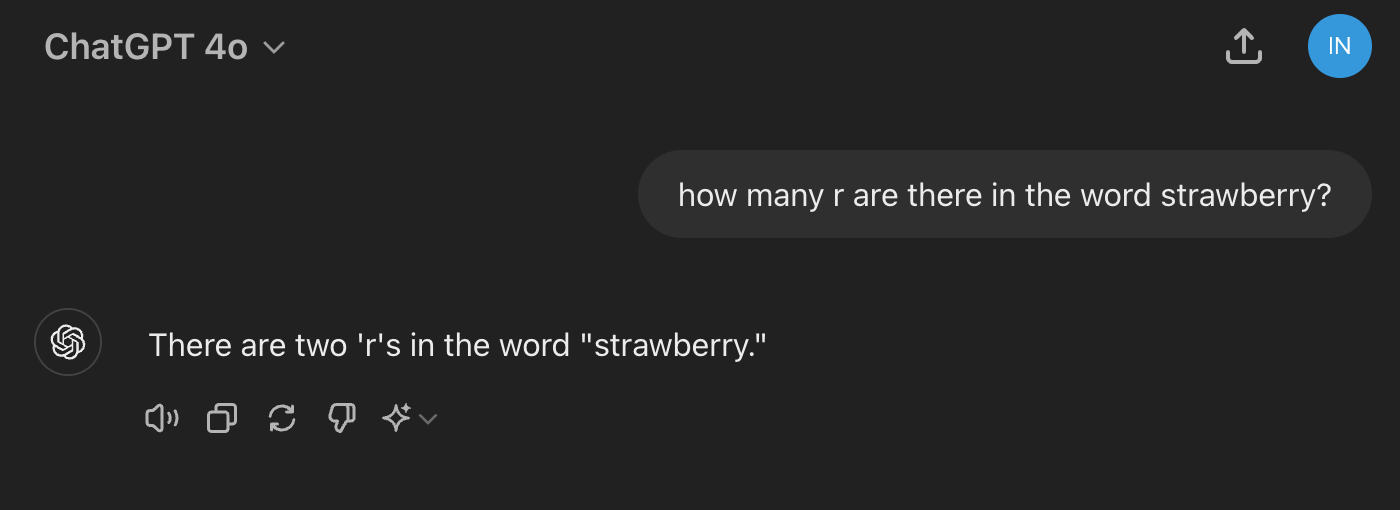
Or how about this one by professor and researcher Subbarao Kambhampati, referenced in a recent New York Times piece:

How should we understand this?
Because of their static nature, LLMs don’t learn from their interactions; or, as Wittgenstein would say, they don’t participate in Sprachspiel. So even if ChatGPT gets it right the second time, it hasn’t learned anything from that back-and-forth. Hit “new chat”, and you’re back to square one.
That’s very different from us. A child can stack a tower of blocks before it learns to speak about it. As humans, we update our knowledge continuously; we are in constant conversation with the world. Both Wittgenstein and Korzybski would probably agree that although the AI has learned all the words in the world, it hasn’t learned anything about how these words relate to the world.
Another way of looking at it is that LLMs are booksmart. They’ve read more books than all of us combined, yet never felt the weight of one in their hand. They can write a ten-page essay about the Golden Retriever, but never felt the joy of coming home to one.
This all ties in beautifully with a concept that I’ve previously described as the Intelligence Paradox. Humans treat language fluency as a proxy for intelligence. As a result of that, we tend to overestimate the capabilities of AI assistants like ChatGPT; because they’re smooth talkers. But we should never forget that to an LLM a truthful statement and a hallucinated response look completely identical. To them, it’s just words. Words that are likely to appear next to other words.
They’re really good map-readers, but never set foot in the garden.
Join the conversation 🗣
Share, like or leave a comment if it resonated with you.
Other works that cover Wittgenstein and AI include:
Graham Button, Jeff Coulter, John Lee, Wes Sharrock: Computers, Minds and Conduct
https://www.politybooks.com/bookdetail?book_slug=computers-minds-and-conduct--9780745615714
Stuart Shankar: Wittgenstein's Remarks on the Foundations of AI (The preface and the first chapter are available for preview):
https://www.taylorfrancis.com/books/mono/10.4324/9780203049020/wittgenstein-remarks-foundations-ai-stuart-shanker
And, of course, there’s also Hubert Dreyfus, who covers both Wittgenstein and Heidegger in his many critiques of AI. In a YouTube video somewhere, Dreyfus comments that the AI people inherited a lemon, a 2,000 old failure. By this he means that from the very beginning AI uncritically adopted assumptions from ancient and early modern philosophy about language, mind, and cognition that are complete nonsense and had already been shown to be such. (This is also true of much of cognitive science, philosophy of mind, neuroscience, etc.) The critique was there long before the famous Dartmouth Workshop. Wittgenstein was debating with Turing at Cambridge in the late 1930s and, after the war, Michael Polanyi was debating these issues with Turing at Manchester.
An engineer in the field of AI who is completely unfamiliar with this literature, might be best to start with Peter Hacker's new intro book:
https://anthempress.com/anthem-studies-in-wittgenstein/a-beginner-s-guide-to-the-later-philosophy-of-wittgenstein-pb
or try his paper on the PLA and the mereological mistake/fallacy:
https://www.pmshacker.co.uk/_files/ugd/c67313_778964f8a7e44b16ac8b86dbf954edda.pdf
Hacker, as far as I know, hasn't directly written directly about AI, but he and Maxwell Bennett (a neuroscientist) have written lengthy critiques of cognitive science (Dennett, Searle, Churchland, Fodor, et al.).
https://www.wiley.com/en-us/Philosophical+Foundations+of+Neuroscience%2C+2nd+Edition-p-9781119530978
It puzzles me that this literature isn't brought up more in current debates about AI. It isn't as if these long-standing critiques have been successfully addressed. The field appears to carry on in either complete ignorance or willful avoidance. "Blah, blah, blah. I can't hear you!" Language is a social institution. A person is not a mind or a brain. Being an AI researcher is like carrying on as an alchemist in a world where the grounds for a science of chemistry have already been laid out for all to see.
I think the argument that they hallucinate does not in fact mean that they don't build a world model - I mean, look at this:
https://www.anthropic.com/research/mapping-mind-language-model
This is a world model of some sort. Hallucinations just mean that the world model can be wrong, and I think that even in the Claude example, it does some odd things like relating "coding error" to "food poisoning" in conceptual space.
But I think I go with Hinton here that it is grasping some sort of meaning(enough to scare me, obviously) and perhaps this should be seen as a matter of degree, with errors. Of course, there are people who also claim that LLMs are discovering Platonic truth, or at least converging to something(maybe all of the same biases?).
https://arxiv.org/pdf/2405.07987