


Claude Plays Pokémon
Here's why we should let AI play more games.

Summary: On Twitch, you can now watch Anthropic’s chatbot Claude trying to beat Pokémon. Games are a great way to test an AI model’s intelligence. Arguably, much better than other benchmarks.
↓ Go deeper (14 min)

I believe the meaning of life is to play. To play is to experiment. To play is to learn. To play is to interact with the world around us and everything in it. This isn’t just true for us, it’s true for animals too. In Homo Ludens, the Dutch historian and cultural theorist Johan Huizinga writes:
“Play is older than culture, for culture, however inadequately defined, always presupposes human society, and animals have not waited for man to teach them their playing.”
Winning at the game of life can mean the difference between life and death, and to a degree, we can infer intelligence from our ability to play.
In the field of artificial intelligence research, play has always had a special place. Computers beating humans at their games have traditionally been seen as historic milestones: Deep Blue beating then world champion Garry Kasparov at chess, AlphaGo beating world no.1 Lee Sedol at the board game Go, and AlphaStar beating pro players at the video game StarCraft II.
While letting AI play games isn’t very fashionable nowadays — for reasons I’ll go into in a sec — I’m happy to report that since a few days ago, you can watch Anthropic’s chatbot Claude play Pokémon live on Twitch.
About 2000 people were exhilarated to see Claude beat the 1st gym leader Brock with a Squirtle named Shell.
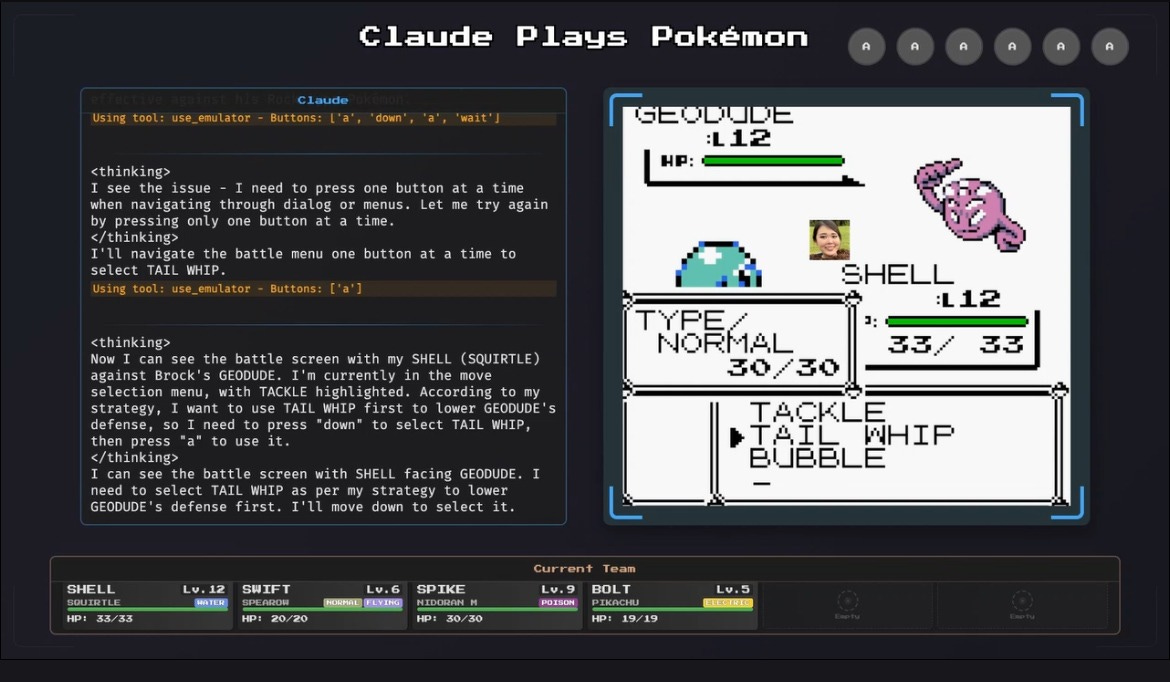
How does Claude play Pokémon?
According to the channel description, ClaudePlaysPokémon is a passion project made by a person who loves Claude and loves Pokémon. Using an emulator, Claude plays through the classic Game Boy game Pokémon Red, without prior training. It tries to beat the game just like a human player would: by looking at the screen to see what’s happening and deciding what to do next.
When Claude wants to act, it can press game buttons in sequence (A, B, Up, Down, Left, Right, Start, Select), navigate to specific coordinates on the screen, and update its knowledge base with new information it discovers. It has a few other tools it can use, but other than that the system is pretty straightforward.

The creator of ClaudePlaysPokémon also notes:
“Until recently, Claude wasn’t good enough to be entertaining, but with the latest model (Claude 3.7 Sonnet) we've made significant progress. The furthest we’ve seen Claude get is past Lt. Surge’s Gym.”
Now, I’ve watch a bit of the stream and I’m not really sure if entertaining is the right word. It’s interesting to watch, for sure, but the reality is that Claude is slow, terribly slow, and it needs to think through every step in minuscule detail.
For reference, beating Brock, the first gym leader in the game, took Claude almost 20 hours to complete. It sometimes gets lost or just simply confused about what it needs to do next or where it’s supposed to go.
At the time of writing, Claude has been stuck in Mt. Moon for more than 18 hours.
ClaudePlaysPokémon is more revealing than almost every other benchmark — and here’s why
The main reason I wanted to cover this story is because I believe these types of experiments tell us much more about a system’s intelligence than any math or coding benchmark.
Give a 10-year old a Nintendo Switch and it can figure out how to play a game in minutes. Yet Claude, Gemini or ChatGPT will mostly fail — they are known to stuggle with simple games like Tic Tac Toe and chess (often resorting to playing illegal moves).
An organization who strongly believes in the importance of play in benchmarking AI models is the ARC Foundation, known for its ARC Prize. Last week, they announced ‘SnakeBench’, a program that lets 50+ different AI models go head-to-head, competing against each other, playing the legendary game Snake.
Here’s what that looks like:

The results were revealing, to say the least. According to the ARC team, reasoning models like OpenAI’s o-models and DeepSeek’s R1 “were in a league of their own”. Topping the leaderboards, o3-mini and DeepSeek won 78% of the matches they played against other LLMs.
They also wrote that “mistakes made most games uninteresting”. Often models failed to visualize the board and track their snake’s position, leading to collisions. It wasn’t until they tested the more advanced frontier models like GPT-4, Gemini 2.0, and o3-mini that they saw enough spatial reasoning for strategic play. (This closely matches with what can be observed in the ClaudePlaysPokémon-experiment.)
The key takeaway here is that the games we ask these AI’s to play are easy for humans, but hard for AI. This is an important insight, because as François Chollet, one of the founders of the ARC Foundation, has repeatedly stated in interviews: as long as we can create simple problems that humans can solve but AI cannot, we have not achieved AGI.
When a measure becomes a target, it seizes to be a good measure
Despite a long history of computers mastering games humans are good at, regretfully, it’s no longer in vogue.
Today’s AI benchmarks tend to revolve almost exclusively around coding, math, and knowledge of various domains. This is, in part, because the new flavor of AI models is significantly more fluent and skilled in language-oriented tasks. They have become the preferred and established way for researchers to gauge a model’s ‘intelligence’ and signal to other labs that they are ahead of each other. Another convenient side-effect of these benchmarks is they are great for showing investors that their billion dollar capital injections are paying off. If the numbers are going up, we are making progression.
The limitations of these benchmarks are well-documented. For one, they tend to rely heavily on memorization. They can be cheated and gamed, data leakage is hard to avoid, and labs tend to be creative with the benchmarks they include in their system cards.
It’s easy to see why. The stakes are high and staying ahead of the competition can be decisive in securing another round of investment or fading into irrelevance. When you’re trying to achieve a higher score for the sake of a higher score — known as Goodhart’s Law — the incentives quickly become misaligned. When the measure becomes the objective, people will tend to optimize for the objective at any cost, including gaming the system.
While there’s value in having a wide variety in benchmarks, we should be careful to make predictions or sweeping statements about a model showing signs of intelligence or “sparks of AGI”. Having AI play games seems to be a much more effective barometer or proxy for that.
The child psychologist Piaget famously said:
“Intelligence is what you use when you don’t know what to do.”
That’s play. To attempt to do what you have never done before.
If you ask me, we have strayed from the path. We should go back to our original ways and let AI play games again to test their ability to think on the fly. To see if they can truly plan and reason. To see if they can adapt to novelty. Learn from their mistakes.
Today’s versions of Claude, Gemini and ChatGPT do not. They can regurgitate all sorts of obscure and less obscure facts (although not entirely reliably) and can solve a wide array of problems by producing long chains of thought. However, whenever you hit refresh, everything they have figured out up until that point is gone. They’ve actually not learned anything at all, which is the biggest difference between them and us.
Perhaps the true AGI benchmark for Claude, or whatever AI comes next, beating Pokémon live on stream. Or maybe another game after that.
On that note, when texting with a friend about writing this article, he did raise a valid point:
Catch you later,
— Jurgen
About the author
Jurgen Gravestein is a product design lead and conversation designer at Conversation Design Institute. Together with his colleagues, he has trained more than 100+ conversational AI teams globally. He’s been teaching computers how to talk since 2018.
Cool article. LLMs learn from prior training, but don't learn actively from active chatting (and/or gaming sessions). It seems that's what kids can do ... iterate and learn in the moment, not by ingesting reams of more data, but from the immediate experience.